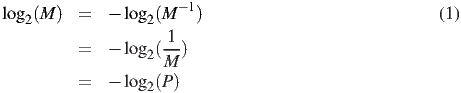
This primer is written for molecular biologists who are unfamiliar with information theory. Its purpose is to introduce you to these ideas so that you can understand how to apply them to binding sites [?, 2, ?, ?, ?, ?, ?, ?, ?]. Most of the material in this primer can also be found in introductory texts on information theory. Although Shannon’s original paper on the theory of information [5] is sometimes difficult to read, at other points it is straight forward. Skip the hard parts, and you will find it enjoyable. Pierce later published a popular book [6] which is a great introduction to information theory. Other introductions are listed in reference [?]. A workbook that you may find useful is reference [?]. Shannon’s complete collected works have been published [?]. Other papers and documentation on programs can be found at
Note: If you have trouble getting through one or more steps in this primer, please send email to me describing the exact place(s) that you had the problem. If it is appropriate, I will modify the text to smooth the path.
Acknowledgments. My thanks go to the many people whose stubbed toes led to this version. Below is an incomplete list. If you gave me comments that resulted in changes to the text and would like your name listed, please tell me the exact date you sent me an email. Amy Caplan, Maarten Keijzer, Frederick Tan, John Hoppner, Huey P. Dugas (Lafayette, Louisiana USA, pointed out that the original coining of nit was by D. K. C. MacDonald [?]), Paul C. Anagnostopoulos for many comments, Fabio Tosques, Izabela Lyon Freire Goertzel, Kevin S. Franco.
Information and Uncertainty
Information and uncertainty are technical terms that describe any process that selects one or more objects from a set of objects. We won’t be dealing with the meaning or implications of the information since nobody knows how to do that mathematically. Suppose we have a device that can produce 3 symbols, A, B, or C. As we wait for the next symbol, we are uncertain as to which symbol it will produce. Once a symbol appears and we see it, our uncertainty decreases, and we remark that we have received some information. That is, information is a decrease in uncertainty. How should uncertainty be measured? The simplest way would be to say that we have an “uncertainty of 3 symbols”. This would work well until we begin to watch a second device at the same time, which, let us imagine, produces symbols 1 and 2. The second device gives us an “uncertainty of 2 symbols”. If we combine the devices into one device, there are six possibilities, A1, A2, B1, B2, C1, C2. This device has an “uncertainty of 6 symbols”. This is not the way we usually think about information, for if we receive two books, we would prefer to say that we received twice as much information than from one book. That is, we would like our measure to be additive.
It’s easy to do this if we first take the logarithm of the number of possible symbols because then we can add the logarithms instead of multiplying the number of symbols. In our example, the first device makes us uncertain by log(3), the second by log(2) and the combined device by log(3)+log(2) = log(6). The base of the logarithm determines the units. When we use the base 2 the units are in bits (base 10 gives digits and the base of the natural logarithms, e, gives nats [?] or nits [?]). Thus if a device produces one symbol, we are uncertain by log21 = 0 bits, and we have no uncertainty about what the device will do next. If it produces two symbols our uncertainty would be log22 = 1 bit. In reading an mRNA, if the ribosome encounters any one of 4 equally likely bases, then the uncertainty is 2 bits.
So far, our formula for uncertainty is log2(M), with M being the number of symbols. The next step is to extend the formula so it can handle cases where the symbols are not equally likely. For example, if there are 3 possible symbols, but one of them never appears, then our uncertainty is 1 bit. If the third symbol appears rarely relative to the other two symbols, then our uncertainty should be larger than 1 bit, but not as high as log2(3) bits. Let’s begin by rearranging the formula like this:
Now let’s generalize this for various probabilities of the symbols, Pi, so that the probabilities sum to 1:
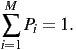 | (2) |
(Recall that the ∑ symbol means to add the Pi together, for i starting at 1 and ending at M.) The surprise that we get when we see the ith kind of symbol was called the “surprisal” by Tribus [7] and is defined by analogy with -log2P to be1
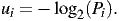 | (3) |
For example, if Pi approaches 0, then we will be very surprised to see the ith symbol (since it should almost never appear), and the formula says ui approaches ∞. On the other hand, if Pi=1, then we won’t be surprised at all to see the ith symbol (because it should always appear) and ui = 0.
Uncertainty is the average surprisal for the infinite string of symbols produced by our device. For the moment, let’s find the average for a string of length N that has an alphabet of M symbols. Suppose that the ith type of symbol appears Ni times so that if we sum across the string and gather the symbols together, then that is the same as summing across the symbols:
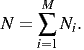 | (4) |
There will be Ni cases where we have surprisal ui. The average surprisal for the N symbols is:
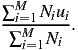 | (5) |
By substituting N for the denominator and bringing it inside the upper sum, we obtain:
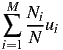 | (6) |
If we do this measure for an infinite string of symbols, then the frequency Ni∕N becomes Pi, the probability of the ith symbol. Making this substitution, we see that our average surprisal (H) would be:2
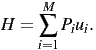 | (7) |
Finally, by substituting for ui, we get Shannon’s famous general formula for uncertainty:
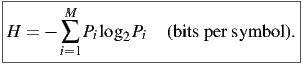 | (8) |
Shannon got to this formula by a much more rigorous route than we did, by setting down several desirable properties for uncertainty, and then deriving the function. Hopefully the route we just followed gives you a feeling for how the formula works.
To see how the H function looks, we can plot it for the case of two symbols. This is shown below3 :
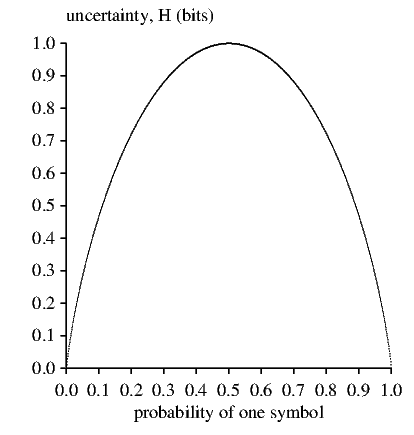
Notice that the curve is symmetrical, and rises to a maximum when the two symbols are equally likely (probability = 0.5). It falls towards zero whenever one of the symbols becomes dominant at the expense of the other symbol.
As an instructive exercise, suppose that all the symbols are equally likely. What does the formula for H (equation (8)) reduce to? You may want to try this yourself before reading on.
*********************************
Equally likely means that Pi = 1∕M, so if we substitute this into the uncertainty equation we get:
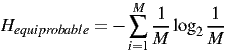 | (9) |
Since M is not a function of i, we can pull it out of the sum:
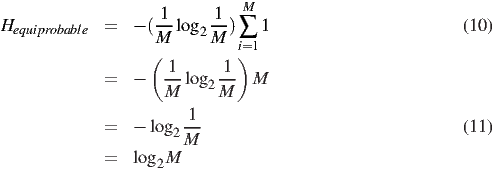
What does it mean to say that a signal has 1.75 bits per symbol? It means that we can convert the original signal into a string of 1’s and 0’s (binary digits), so that on the average there are 1.75 binary digits for every symbol in the original signal. Some symbols will need more binary digits (the rare ones) and others will need fewer (the common ones). Here’s an example. Suppose we have M = 4 symbols:
 | (12) |
with probabilities (Pi):
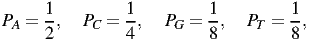 | (13) |
which have surprisals (-log2Pi):
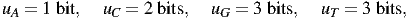 | (14) |
so the uncertainty is
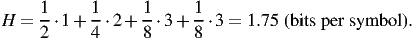 | (15) |
Let’s recode this so that the number of binary digits equals the surprisal:
so the string
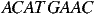 | (17) |
which has frequencies the same as the probabilities defined above, is coded as
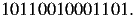 | (18) |
14 binary digits were used to code for 8 symbols, so the average is 14/8 = 1.75 binary digits per symbol.
This is called a Fano code. Fano codes have the property that you can decode them without
needing spaces between symbols. Usually one needs to know the “reading frame”, but in
this example one can figure it out. In this particular coding (equations (16)), the first binary
digit distinguishes between the set containing A, (which we symbolize as {A}) and the set
{C,G,T }, which are equally likely since 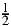 =
= 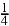 +
+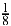 +
+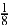 . The second digit, used if the first
digit is 0, distinguishes C from G,T . The final digit distinguishes G from T . Because each
choice is equally likely (in our original definition of the probabilities of the symbols), every
binary digit in this code carries 1 bit of information. Beware! This won’t always be true. A
binary digit can supply 1 bit only if the two sets represented by the digit are equally likely (as
rigged for this example). If they are not equally likely, one binary digit supplies less than one
bit. (Recall that H is at a maximum for equally likely probabilities.) So if the probabilities
were
. The second digit, used if the first
digit is 0, distinguishes C from G,T . The final digit distinguishes G from T . Because each
choice is equally likely (in our original definition of the probabilities of the symbols), every
binary digit in this code carries 1 bit of information. Beware! This won’t always be true. A
binary digit can supply 1 bit only if the two sets represented by the digit are equally likely (as
rigged for this example). If they are not equally likely, one binary digit supplies less than one
bit. (Recall that H is at a maximum for equally likely probabilities.) So if the probabilities
were
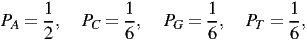 | (19) |
there is no way to assign a (finite) code so that each binary digit has the value of one bit (by using larger blocks of symbols, one can approach it).4 In the rigged example, there is no way to use fewer than 1.75 binary digits per symbol, but we could be wasteful and use extra digits to represent the signal. The Fano code does reasonably well by splitting the symbols into successive groups that are equally likely to occur; you can read more about it in texts on information theory. The uncertainty measure tells us what could be done ideally, and so tells us what is impossible. For example, the signal with 1.75 bits per symbol could not be coded using only 1 binary digit per symbol.
Tying the Ideas Together
In the beginning of this primer we took information to be a decrease in uncertainty. Now that we have a general formula for uncertainty, (8), we can express information using this formula. Suppose that a computer contains some information in its memory. If we were to look at individual flip-flops, we would have an uncertainty Hbefore bits per flip-flop. Suppose we now clear part of the computer’s memory (by setting the values there to zero), so that there is a new uncertainty, smaller than the previous one: Hafter. Then the computer memory has lost an average of5
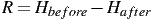 | (20) |
bits of information per flip-flop. If the computer was completely cleared, then Hafter = 0 and R = Hbefore.
Now consider a teletype receiving characters over a phone line. If there were no noise in the phone line and no other source of errors, the teletype would print the text perfectly. With noise, there is some uncertainty about whether a character printed is really the right one. So before a character is printed, the teletype must be prepared for any of the letters, and this prepared state has uncertainty Hbefore, while after each character has been received there is still some uncertainty, Hafter. This uncertainty is based on the probability that the symbol that came through is not equal to the symbol that was sent, and it measures the amount of noise.
Shannon gave an example of this in section 12 of [5] (pages 33-34 of [?]). A system with two equally likely symbols transmitting every second would send at a rate of 1 bit per second without errors. Suppose that the probability that a 0 is received when a 0 is sent is 0.99 and the probability of a 1 received is 0.01. “These figures are reversed if a 1 is received.” Then the uncertainty after receiving a symbol is Hafter = -0.99log20.99-0.01log20.01 = 0.081, so that the actual rate of transmission is R = 1-0.081 = 0.919 bits per second.6 The amount of information that gets through is given by the decrease in uncertainty, equation (20).
Unfortunately many people have made errors because they did not keep this point clear. The errors occur because people implicitly assume that there is no noise in the communication. When there is no noise, R = Hbefore, as with the completely cleared computer memory. That is if there is no noise, the amount of information communicated is equal to the uncertainty before communication. When there is noise and someone assumes that there isn’t any, this leads to all kinds of confusing philosophies. One must always account for noise.
One Final Subtle Point. In the previous section you may have found it odd that I used the word “flip-flop”. This is because I was intentionally avoiding the use of the word “bit”. The reason is that there are two meanings to this word, as we mentioned before while discussing Fano coding, and it is best to keep them distinct. Here are the two meanings for the word “bit”:
